
{kind=link}
Revolutionary AI Language Models Take the Stage
Written by: Alex Smith
– Mar 15, 2025 9:30 am EST

View Larger Image / Behold, the newest Claude 3 logo.
{kind=link}
In a groundbreaking release, Anthropic unveiled Claude 3, a trio of AI language models similar to those powering ChatGPT. Anthropic boasts that these models have set unprecedented industry standards across various cognitive tasks, even reaching “nearly human” levels of performance in certain scenarios. Interested individuals can now access Claude 3 through Anthropic’s website, with the most advanced model exclusive to subscribers. Additionally, developers can utilize Claude 3 through an API.
The three models within the Claude 3 family represent a progression in complexity and parameter count: Claude 3 Haiku, Claude 3 Sonnet, and Claude 3 Opus. While Sonnet currently fuels the Claude.ai chatbot for free with an email sign-up, Opus can only be accessed through Anthropic’s web chat platform for a subscription fee of $20 per month through “Claude Pro.” All three models boast a 200,000-token context window, allowing them to process a significant amount of information at once.
In the past, Anthropic introduced Claude in March 2023 and Claude 2 in July of the same year. Although these releases slightly trailed behind OpenAI’s top models in performance, they excelled in terms of context window length. With the launch of Claude 3, Anthropic appears to have potentially caught up with OpenAI’s models in terms of overall performance. However, there is no unanimous agreement among experts, as AI benchmark comparisons often involve selective data interpretation.
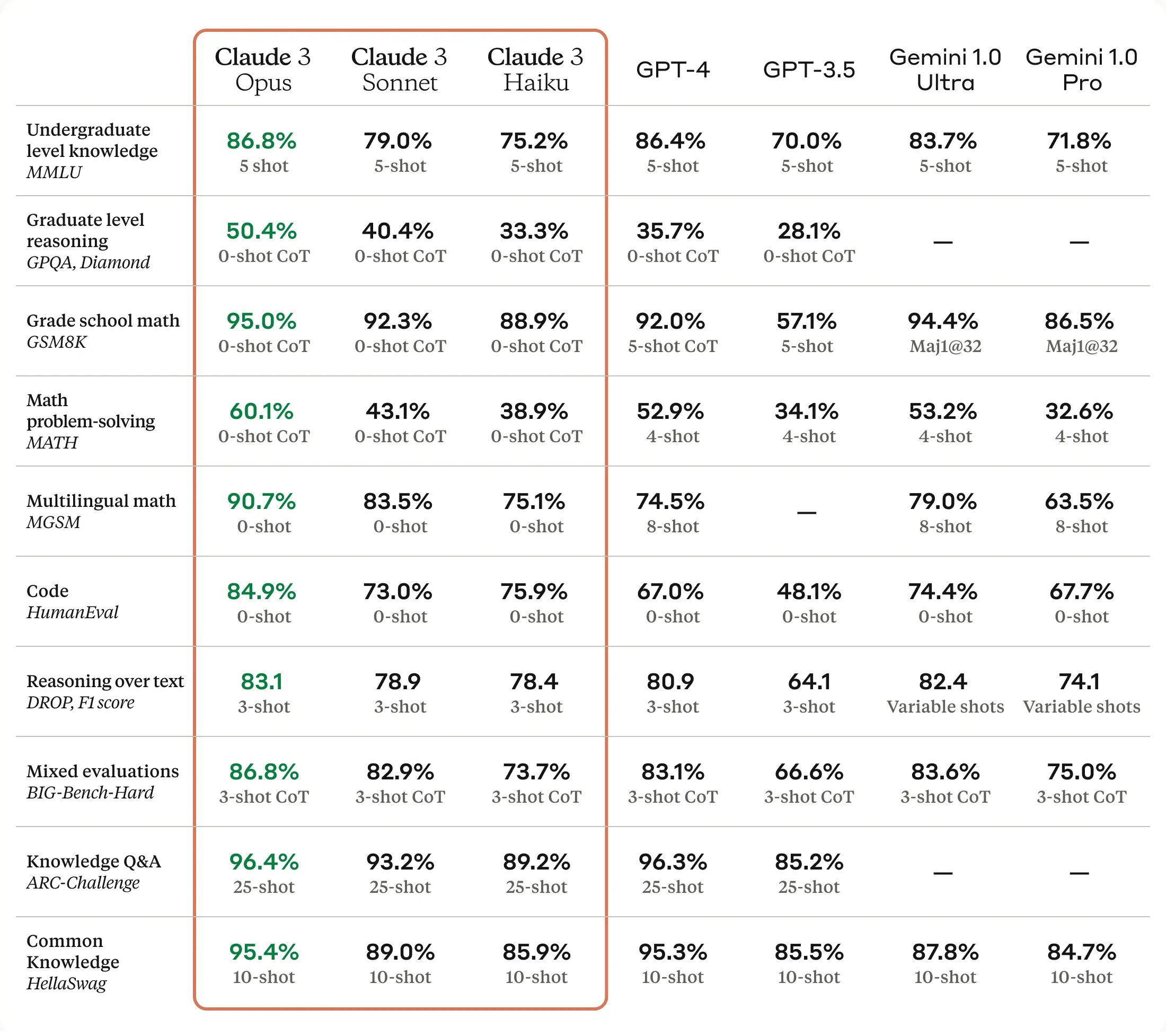
View Larger Image / An informational infographic showcasing Claude 3’s benchmarks, as shared by Anthropic.
Reportedly, Claude 3 showcases exceptional performance across a variety of cognitive tasks, including reasoning, expert knowledge, mathematics, and linguistic fluency. Despite ongoing debates within the AI research community regarding whether large language models possess knowledge or reasoning capabilities, these terms are commonly used. Anthropic suggests that the Opus model, the most advanced among the three, demonstrates comprehension and fluency levels akin to human standards on intricate tasks.
Although the claim of Opus reaching “nearly human” levels of performance is attention-grabbing, it warrants further examination. While Opus may excel in specific benchmarks, it does not equate to possessing general human-like intelligence (much like how calculators surpass human capabilities in math). Hence, this assertion, while intriguing, should be qualified and scrutinized.
Anthropic affirms that Claude 3 Opus outperforms GPT-4 in 10 AI benchmarks, encompassing categories such as undergraduate-level knowledge, grade school mathematics, coding, and general knowledge assessments. The victories range from narrow margins, like Opus surpassing GPT-4 by 0.4 percent in a five-shot trial of MMLU, to substantial differences, such as Opus achieving 90.7 percent on HumanEval compared to GPT-4’s 67.0 percent. The implications of these results for consumers remain somewhat ambiguous and require deeper exploration.